Por Thiago Hersan e Giselle Beiguelman
Em colaboração com o projeto Arquigrafia, experimentamos diferentes modelos de Visão Computacional 1 para analisar imagens de um acervo de arquitetura, do qual extraímos dados sobre arte e design, criando camadas de legibilidade do acervo que não eram visíveis no formato de sua catalogação original. Estes recursos estão disponíveis no protótipo que disponibilizamos no nosso GitHub e aprofundam os experimentos feitos a partir dos vídeos das câmeras de segurança do Palácio do Planalto em 8 de janeiro de 2023.
O site arquigrafia.org.br é um ambiente colaborativo na internet que, desde 2008, mantem um espaço público, aberto e gratuito, para fomentar a construção de uma coleção de imagens digitais de edifícios e espaços urbanos do Brasil a partir da participação dos seus usuários, aqui denominados de “comunidade Arquigrafia”.
A motivação de usar recursos de Visão Computacional no tratamento de seus dados visou complementar as informações fornecidas pelo público e versatilizar as pesquisas feitas nesse acervo, expandindo as informações sobre arquitetura, para a identificação de outros elementos contidos nessas imagens, como elementos arquitetônicos (janelas, portas, escadas etc.), design (mobiliário), arte (pintura e escultura), além de novas categorias, como vegetação.
Análise da Arquitetura de Informação
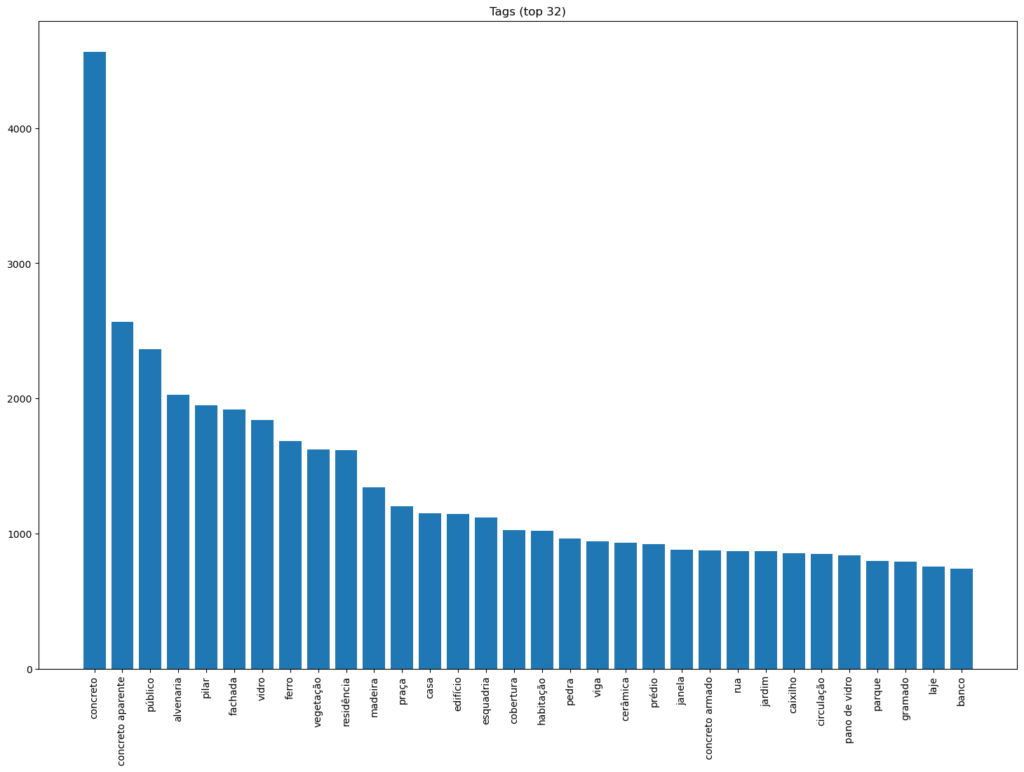
A primeira etapa do nosso trabalho envolveu compreender sua arquitetura de informação, por meio da análise das adições do público, do ponto de vista da distribuição das palavras-chave (tags), adicionadas às imagens enviadas. O acervo do Arquigrafia conta com mais de 15 mil imagens e 76 mil tags (palavras-chave) definidas pelos seus usuários. Algumas imagens têm 50 tags para descrever o conteúdo da imagem, enquanto outras não tem nenhuma. Isso nos permitiu compreender as ênfases do público, seus interesses e quais campos ausentes e de interesse poderíamos complementar com o uso de Visão Computacional. Para esta etapa, contamos com o trabalho da pesquisadora Ana Carolina Ribeiro Costa, da equipe Arquigrafia, coordenada pelo Prof. Artur Rozestraten.
Detecção de objetos
Para implantar os recursos de busca com Visão Computacional, utlizamos o modelo de detecção de objetos OWL-ViT-v2, um modelo de vocabulário aberto para detectar objetos e materiais relacionados à arquitetura e design. Modelos de vocabulário aberto são aqueles que foram treinados de forma genérica, com imagens e textos, e aprendem a detectar objetos, que não fazem parte das imagens de treinamento. São ideais para fazer testes rápidos e protótipos, antes de investir em modelos mais específicos.
Os objetos detectados estão distribuídos nas seguintes categorias:
- Arquitetura: portas, janelas, torres, vegetação, rampas, sacadas, corrimãos/balaustres, escadas, colunas
- Materiais: concreto, alvenaria, metal, vidro, madeira
- Design: cadeiras, mesas,
- Arte: quadros, estátuas/esculturas
Alguns exemplos:



Descobertas
Percebemos que algumas das categorias identificadas com inteligência artificial, como portas e árvores, são reconhecidas com facilidade, provavelmente por estarem presente nas imagens de treinamento. Outras categorias mais especifícas à arquitetura, como rampas e sacadas, não são sempre detectadas.
Dado que o modelo utilizado é treinado de forma genérica, tivemos que usar um pouco de criatividade para descrever alguns objetos, utlizando palavras, menos específicas para guiar o processo de detecção. Por exemplo, os termos “building door” e “room door” são usados para detectar portas, sejam eles portões ou passagens, enquanto os termos “minaret”, “tower” e “chimney” são usados pelo modelo para detectar estruturas salientes no topo de construções, a despeito de serem caixas-dágua ou sótãos.
A partir da identificação dos dos erros automatizados iniciais, revisados por Ana Roman, Cassia Hosni, Milena Szafir e Renata Perim, pesquisadoras do nosso projeto, mapeamos algumas das deficiências de modelos pré-treinados e confirmamos uma necessidade (e oportunidade) para criar modelos mais específicos às àreas de arquitetura e urbanismo.
Descrição de imagens
Além da detecção de objetos nas fotos do acervo também usamos modelos de análise de imagens para gerar descrições para cada uma das fotos.
Essas descrições trazem informações sobre a cena capturada pela foto e não só sobre objetos e suas características arquitetônicas. Além de ampliar a potência de leituras das imagens arquivadas no Arquigrafia, atendem uma prerrogativa fundamental dos nossos Projetos Temáticos Fapesp (Acervos Digitais e Pesquisa e Arquigrafia) de transformar arquivos em instrumentos de inclusão política e social. No caso, o foco principal é permitir que um arquivo de imagens atenda também pessoas com deficiência visual e pessoas idosas.
Descobertas
Muitas vezes essas descrições envolvem frases muito subjetivas e hiperbólicas. Para tanto, foi implementado um processo de filtragem, “forçando” que a visão computacional extraísse somente as palavras-chave e substantivos em sua varredura da imagem.
Exemplos:

Descrição original:
Imagem mostra uma cena de rua animada com pessoas andando entre prédios coloridos, barracas de mercado e grandes árvores
Descrição filtrada (revisão do algoritmo):
Imagem de pessoas, prédios, barracas de mercado, árvores
Essas frases podem ser usadas tanto para indexar buscas no acervo original do arquigrafia.org.br, quanto para gerar áudios descritivos, feature a ser implementado, ampliando seu aspecto inclusivo. A revisão de uma amostra de 1.000 imagens feita pelas pesquisadoras Ana Roman, Cassia Hosni, Milena Szafir e Renata Perim foi também fundamental para atingirmos os objetivos propostos.
Análise cromática
Outro tipo de análise automatizada que implementamos, sugerida por nossos parceiros do Arquigrafia, foi uma análise cromática que calcula as cores dominantes de cada foto. Acreditamos que organizar as fotos por cor seja uma estratégia interessante para catalogar um acervo do porte do Arquigrafia e uma ferramenta de busca relevante para sua comunidade e pesquisadores das áreas de arquitetura, design e arte.
O algoritmo usado para esse calculo foi o k-nearest neighbors (ou, k vizinhos próximos), um algoritmo de aprendizagem não-supervisionada2. No caso da análise cromática, esse algoritmo encontra um número “k” de cores para representar todas as cores da imagem. Esse é um dos cálculos usados no efeito de posterização do Photoshop e outros programas de edição de imagens.
A nossa versão do algoritmo KNN usa k=4 para extrair as 4 cores dominantes de cada imagem. Nosso algoritmo também foi levemente modificado para usar cores representadas em HSV (Hue (matiz), Saturation (saturação) e Value (valor)), ao invés do sistema RGB (Red (vermelho), Green (verde) e Blue (azul), permitindo despriorizar tons cinzas. O sistema considera os tons pretos, brancos e cinzas das imagens, mas as modificações implementadas fazem com que cores mais saturadas sejam priorizadas, no processo de calcular as 4 cores dominantes de uma imagem.
A partir da análise cromática podemos re-organizar o acervo e listar imagens por ordem de similaridade a cores específicas ou por seus valores de brilho, saturação ou luminosidade, conforme se vê abaixo:




Para testar, acesse o protótipo
Leia também: Acervos em Movimento – Documentação Social, IA e Curadoria Colaborativa
Notas
- A Visão Computacional é um sistema que lê, interpreta e extrai dados de arquivos digitais. Sua aplicação é ampla, abrangendo OCR (reconhecimento óptico de caracteres), exames médicos, programas de busca, modelagem 3D, vigilância, biometria, carros autônomos e várias técnicas de edição de imagem. Computadores não enxergam e, por isso, quando falamos em VC estamos nos referindo a um modelo de Inteligência Artificial treinado para reconhecer e interpretar algoritmicamente matrizes de pontos, dados e informações disponíveis nas camadas de uma arquivo digital de imagem ↩︎
- Sistemas não supervisionados empregam modelos pré-treinados em imagens não rotuladas para fins específicos, permitindo que sejam adaptados em diferentes contextos. ↩︎